TINC - Tree-structured Implicit Neural Compression
Introduction
Compression
- Traditional Compression
- JPEG, JPEG2000, H.264, HEVC
- Deep-Learning Based Method
Compression for Different data type: For image and videos, ok. For Biomedia data, ?
--
Introduction
- INR-Based Compression
- NeRV: Neural Representations for Videos
- SCI: A Spectrum Concentrated Implicit Neural Compression for Biomedical Data
--
技巧💡
- Ensemble learning (Position encoding can be seen as Ensemble Learning for high accuracy, but for compression task is not optimal. ? )
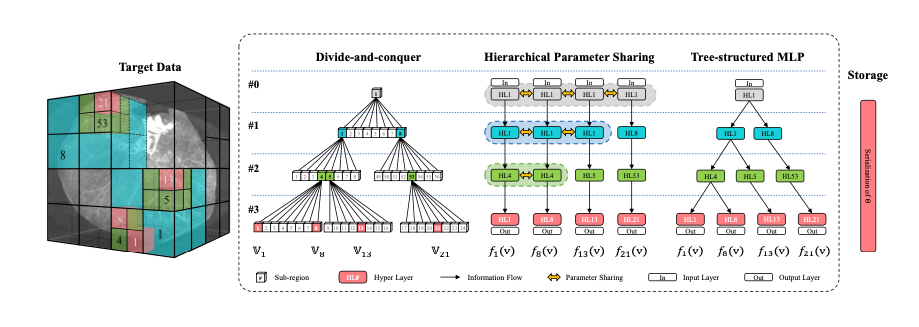
- Divide- and-conquer strategy
Compress different regions with multiple MLPs separately, incorporate these MLPs with a tree structure to extract their shared parameters hierarchically
Method
The scheme of the proposed approach TINC
Problem Settings
- Compression Data :
- grid coordinates :
- intensity value at coordinate
:
For a neural network with parameter: , minimize the loss between
- grid coordinates :
Ensemble Learning
Partition the target volume into blocks and use multiple less expressive
Hierarchical parameter sharing mechanism
Hierarchical parameter sharing mechanism
- Each Level contains the parameters of the INR
- Leaf Node's input is the output of its parent node
- As the figure
Cross level parameter allocation
The number of tree levels L
- The number of the parameter is set to a const number, so with the increase of the depth of the tree
, The sub-layer in each level is smaller,
Inter-level parameter allocation
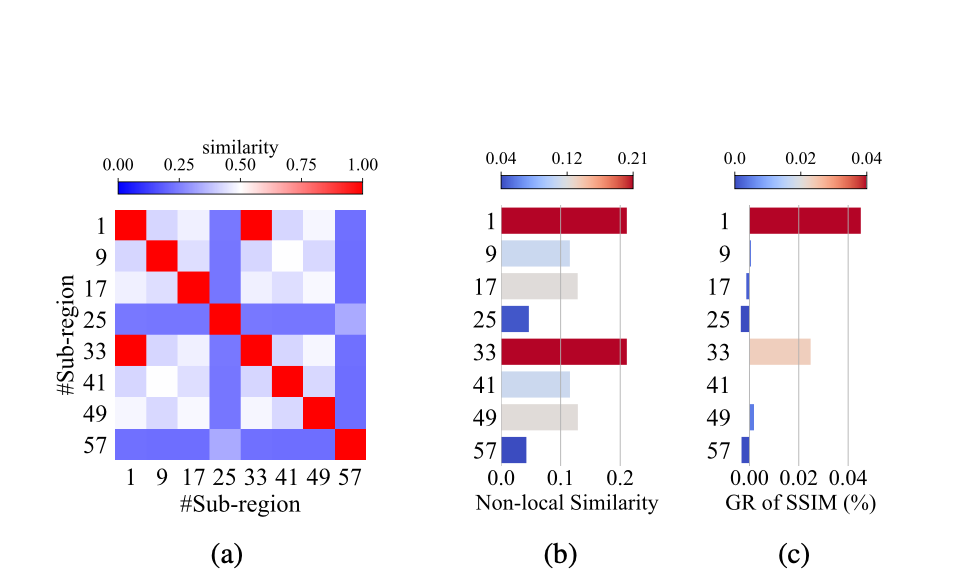
- Key Point: The parameters at the shallow level describe the shared features at large scale, the non-local redundancy distributed over distant regions. Similarly, from the perspective of data features, if some far apart sub-regions at a certain level are highly similar, one can allocate more parameters to their common ancestor nodes, and vice versa.
- Therefore, for data with high global redundancy or repetitiveness, i.e., high non-local similarity among sub-regions at large scales, allocating more parameters to the shallow level will be more beneficial to improve its compression fidelity. Conversely, for data with weak global similarity, it is more efficient to allocate more parameters to the nodes at deep levels for better representation of the unique local features.
Intra-level parameter allocation
- Key Point : allocate more parameters within a level to some nodes according to certain criteria instead of even allocation. For example, the most valuable information in neuronal data is often distributed in sparser regions.
- A simple way to take advantage of the TINC’s hierarchy and flexibility is to allocate the number of parameters per node at each level according to the importance of the corresponding regions
Experiments
例子
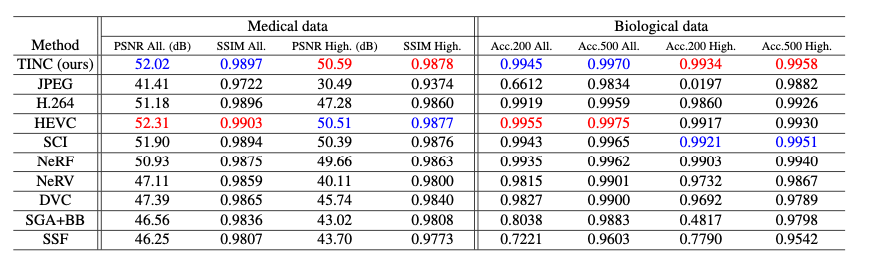
例子
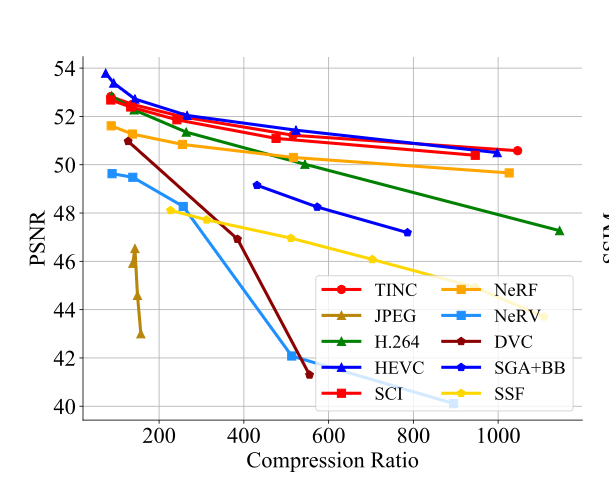
例子
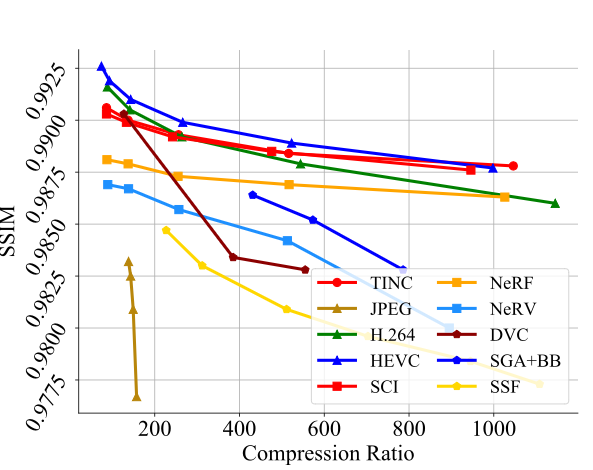
例子
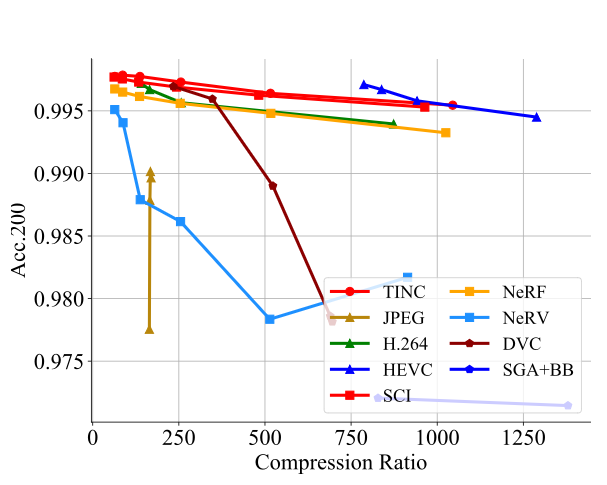
例子
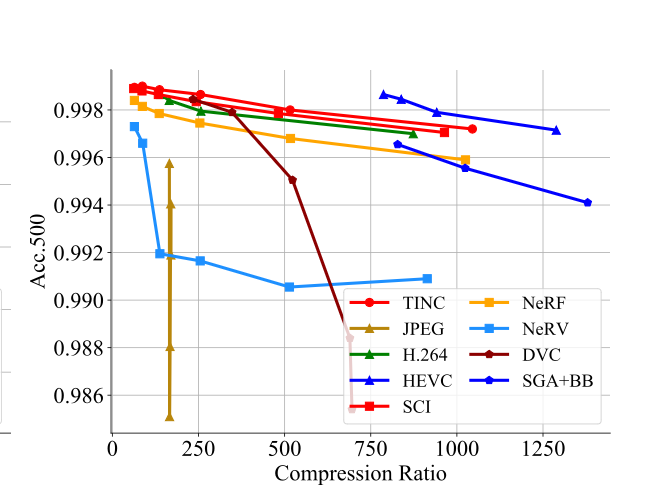
例子
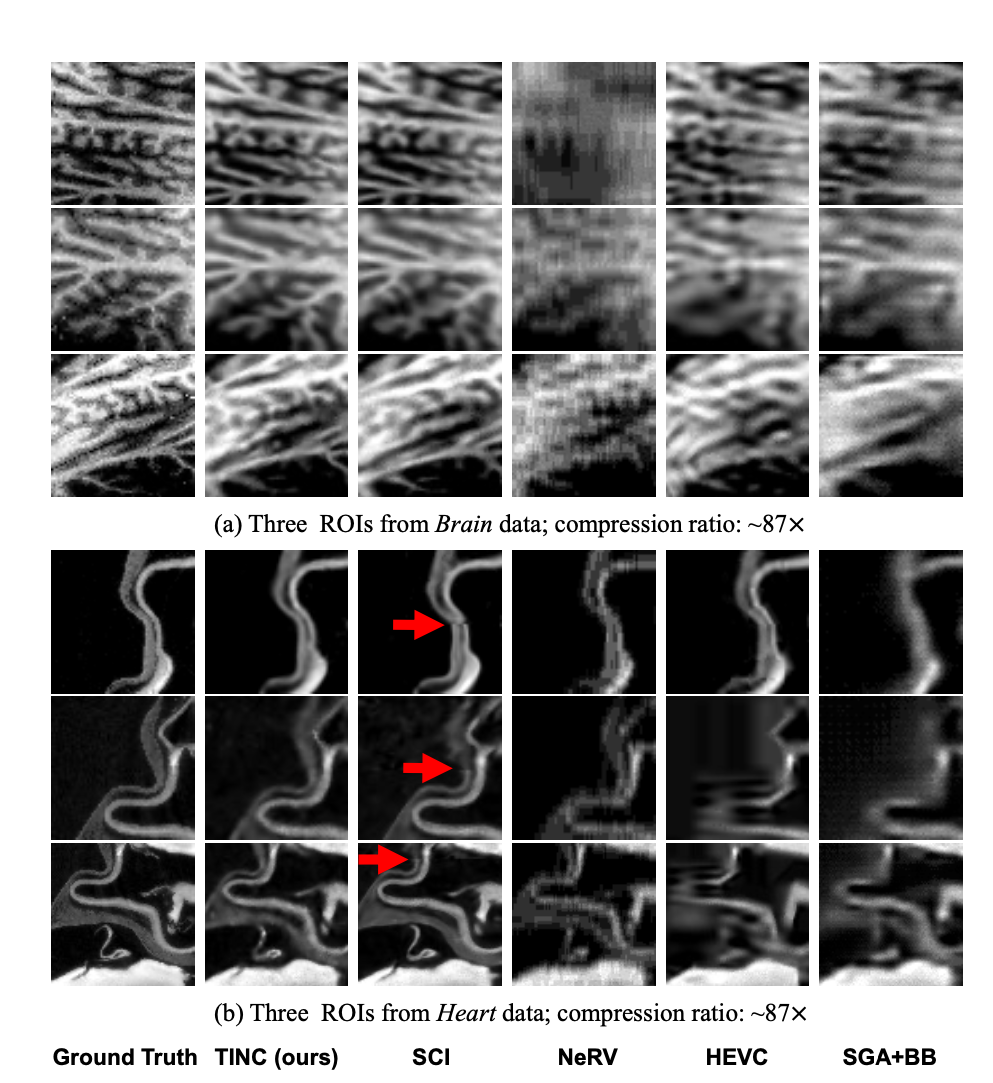
例子
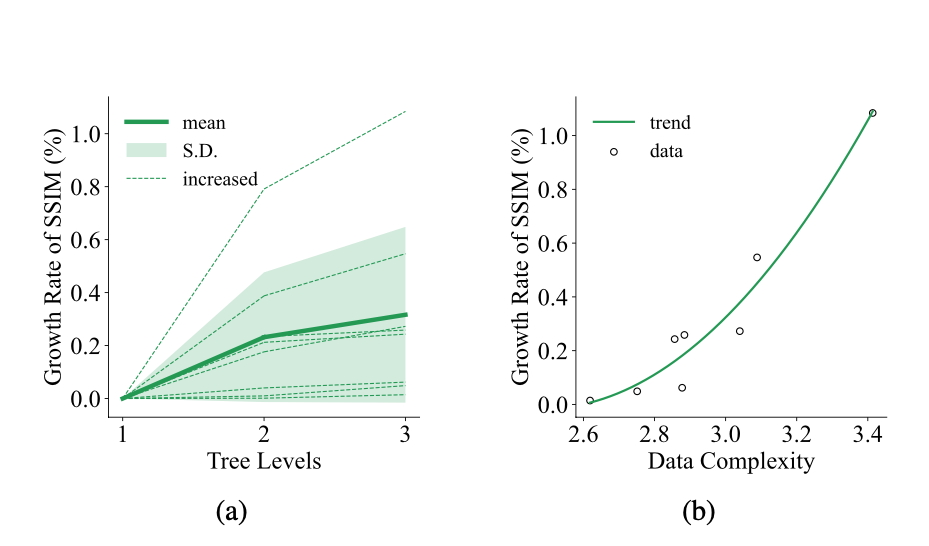
例子